목적
- CIFAR-10 데이터셋을 사용하여 CNN의 학습 설정에 따른 성능 변화를 분석
- AlexNet의 주요 기법(ReLU, Dropout, Overlapping Pooling, LRN 등)이 CIFAR-10에서 주는 효과를 검증하고자 함
공통 실험 환경
- optimizer = Adam(lr=0.001)
- batch_size = 64
- epoch = 10
- 데이터셋: CIFAR-10 (3×32×32 RGB)
실험 1: 활성화 함수별 학습 성능 비교 (ReLU / Sigmoid / _Tanh)
실험 환경
- 모델: SimpleCNN
- 변수: 활성화 함수 [ReLU, Sigmoid, Tanh]
- 고정: optimizer = Adam, lr = 0.001, batch_size = 64, epoch = 10
- 데이터셋: CIFAR-10 (3×32×32 RGB) 데이터 분할 및 전처리
- Train / Validation / Test = 40,000 : 10,000 : 10,000
- 검증 데이터 비율: 0.2 (20%)
- 정규화: 픽셀값 [0, 1] 스케일링
모델 구조
- 입력: (3, 32, 32) CIFAR-10 컬러 이미지
- Conv 블록 1: Conv2d(3→32, 3×3) → BatchNorm → ActivationFn[ReLU, Sigmoid, Tanh] → MaxPool(2×2)
- Conv 블록 2: Conv2d(32→64, 3×3) → BatchNorm → ActivationFn[ReLU, Sigmoid, Tanh] → MaxPool(2×2)
- FC 블록: Flatten → Linear(4096→128) → ActivationFn[ReLU, Sigmoid, Tanh] → Dropout(0.5) →Linear(128→10)
- 출력:(B, 10), softmax는 `CrossEntropyLoss`에서 처리
실험 내용
- 동일한 모델구조를 통해 활성화 함수(ReLU, Sigmoid, Tanh)가 CNN의 학습 성능에 미치는 영향을 비교.
- 모든 실험에서 optimizer는 Adam, 학습률은 0.001, batch size는 64로 고정.
- CIFAR-10 데이터셋을 40,000/10,000/10,000으로 분할하여 학습·검증·테스트에 사용.
실험 상세
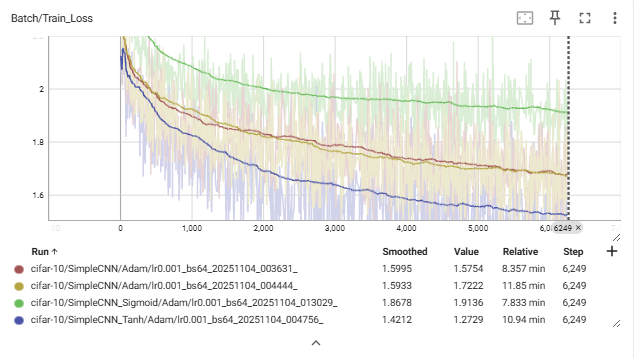
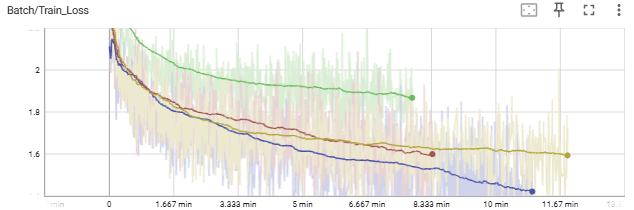 Train Loss 그래프:
Train Loss 그래프:
- Tanh (파란색) → 가장 빠르게 안정적으로 감소.
- ReLU (빨간/노란색) → 완만하게 감소.
- Sigmoid (초록색) → 감소 정체.
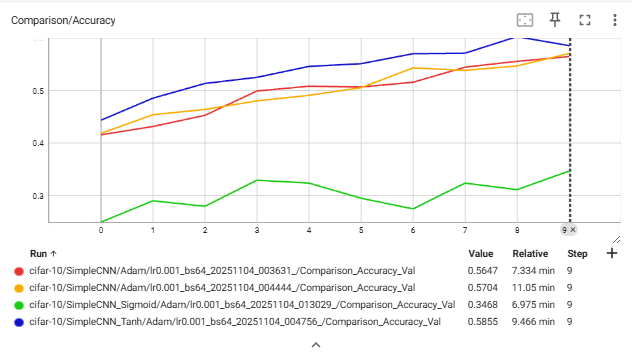 Val Accuracy 그래프:
Val Accuracy 그래프: - Tanh > ReLU ≫ Sigmoid
- Tanh는 epoch이 늘어날수록 꾸준히 증가.
- Sigmoid는 거의 향상 없음.
정리
- ReLU (빨간/노란색)
- 손실 감소가 완만하며, 학습 초반 변동이 존재함.
- Sigmoid (초록색)
- 손실 감소가 거의 진행되지 않음.
- 전체 학습 과정에서 정확도 향상 폭이 가장 낮음.
- Tanh (파란색)
- 손실이 가장 빠르고 안정적으로 감소함.
- ReLU보다 빠른 수렴을 보이며, 검증 정확도 또한 가장 높음.
- 종합 관찰
- Tanh > ReLU ≫ Sigmoid 순으로 성능 차이를 보임.
- 동일한 조건(Adam, lr=0.001, epoch=10)에서도 활성화 함수 선택이 수렴 속도와 최종 정확도에 뚜렷한 영향을 미침.
결론
- ReLU가 제일 높은 정확도와 낮은 손실을 기록할거라 예상했지만 본 실험 환경에서는 Tanh가 ReLU보다 낮은 손실과 높은 정확도를 보임.
- 모델의 구조적 한계
- 낮은 정확도
- 잘못된 활성화 함수 비교
고찰
- 모델 구조적 한계
- 모델의 layer가 적어 ReLU의 희소 활성화 특성이 비효율적으로 작용했음.
- 비선형 표현력이 제한되어 깊은 피처 학습이 어려웠음.
- GPU 사용량 저조(너무 긴 학습 시간)
- 간단한 모델임에도 학습에 너무 긴 시간이 걸림
실험 2: 활성화 함수별 학습 성능 비교 개선된 모델(ReLU / _Tanh)
실험 환경
- 모델: ImprovedCNN
- 변수: 활성화 함수 [ReLU, Tanh]
- 고정: optimizer = Adam, lr = 0.001
- 데이터셋: CIFAR-10 (3×32×32 RGB) 데이터 분할 및 전처리
- Train / Validation / Test = 40,000 : 10,000 : 10,000
- 검증 데이터 비율: 0.2 (20%)
- 정규화: 픽셀값 [0, 1] 스케일링
모델 구조
- 입력 : (3, 32, 32) CIFAR-10 컬러 이미지
- Feature Extractor 블록
- Conv2d(3→32, 3×3) → BatchNorm → ActivationFn[ReLU/Tanh]
- Conv2d(32→64, 3×3) → BatchNorm → ActivationFn[ReLU/Tanh] → MaxPool(2×2)
- Conv2d(64→128, 3×3) → BatchNorm → ActivationFn[ReLU/Tanh]
- Conv2d(128→128, 3×3) → BatchNorm → ActivationFn[ReLU/Tanh] → MaxPool(2×2)
- Conv2d(128→256, 3×3) → BatchNorm → ActivationFn[ReLU/Tanh]
- Conv2d(256→256, 3×3) → BatchNorm → ActivationFn[ReLU/Tanh] → MaxPool(2×2)
- Classifier 블록
- Flatten → Linear(256×4×4→256) → ActivationFn[ReLU/Tanh] → Dropout(0.5) → Linear(256→10)
- 출력 : (B, 10) – `CrossEntropyLoss` 로 softmax 처리
실험 내용
- 실험 1(SimpleCNN)에서는 Tanh가 ReLU보다 더 높은 정확도를 보였으나, 이는 모델이 얕아서 생기는 문제라 생각됨.
- GPU 사용량이 저조한 것은 과도한 이미지 증강으로 CPU에서 작업이 오래 걸려 병목 생기는 가능성일 거라 생각됨.
- ImprovedCNN은 네트워크 깊이 확장(Conv 6층, 채널 32→256), 데이터 증강의 완화(최적화)를 통해 실험 1의 결과를 재검증하려고 함.
실험 상세
Train Accuracy
- ReLU: 빠르고 안정적인 상승 (최종 0.97 근처)
- Tanh: 학습 속도 느리고 포화 현상으로 0.75 근처에서 정체
Train Loss
- ReLU: 초기 급감 후 0.1 근처에서 안정화
- Tanh: 손실 감소 완만, 진동 폭 큼
Validation Accuracy
- ReLU: 최대 0.88~0.86
- Tanh: 0.74~0.54
→ 실험 1과 달리 ReLU가 역전하여 우세
Validation Loss
- ReLU: 0.55~0.67 근처 안정
- Tanh: 1.0 이상에서 진동 지속
Batch-Level Loss
- ReLU (Batch=512): 가장 빠르고 안정적인 수렴 (최종 손실 ≈ 0.11)
- Tanh (Batch=512): 포화로 인해 손실 0.7 이상 유지
→ ReLU는 batch 크기와 관계없이 일관된 손실 감소를 보임
정리
| 설정 | 활성화 함수 | Batch | Epoch | Train Acc | Val Acc | Val Loss |
|---|---|---|---|---|---|---|
| Adam(lr=0.005) | ReLU | 512 | 100 | 0.972 | 0.8858 | 0.565 |
| Adam(lr=0.005) | ReLU | 64 | 100 | 0.928 | 0.855 | 0.674 |
| Adam(lr=0.005) | Tanh | 512 | 50 | 0.757 | 0.749 | 1.09 |
| Adam(lr=0.005) | Tanh | 64 | 50 | 0.495 | 0.543 | 1.28 |
- ReLU
- 빠른 손실 감소 및 높은 안정성
- 깊은 구조에서 gradient 흐름 유지 → 과적합 없이 높은 일반화 성능
- Tanh
- 포화 구간 진입으로 gradient vanishing 발생
- 깊은 층에서 학습 속도 및 정확도 저하
결론
- ImprovedCNN 환경에서 ReLU가 Tanh를 명확히 상회하는 성능을 보임.
- 깊은 구조에서는 ReLU의 비선형성 및 gradient 유지 특성이 강점으로 작용.
- Tanh는 안정적이지만, 깊은 층에서 포화로 인해 학습 효율 저하.
- 실험 1과 달리 구조적 제약이 해소된 환경에서
ReLU > Tanh 순으로 성능이 역전됨을 확인.
고찰
- 모델의 깊이에 따른 활성화 함수 효율성:
- 얕은 구조에서는 Tanh의 연속적 활성화가 빠른 초기 수렴을 보일 수 있지만, 깊은 구조에서는 ReLU의 비포화 영역 특성이 gradient 소실을 방지하며 학습 효율을 극대화.
- DataAugmentation은 Dataset에 맞게 사용하기
CIFAR-10 실험 이후
- Early Stopping 알아보기
- Dying ReLU 문제 / ReLU 변형 함수 찾아보기
- Precision, F1-score 등 다양한 metric 기법 활용해보기